Robot Terror
Tech experiments, travel adventures, and code explorations by Robert Taylor
Building a Complete Local LLM Ecosystem: Stack Deployment and Performance Benchmarking
by Robert Taylor
Running large language models locally has become increasingly practical, especially on Apple Silicon hardware with its unified memory architecture and Metal Performance Shaders acceleration. However, setting up a reliable local LLM environment and understanding its performance characteristics requires the right tooling. Today I’m sharing two complementary repositories that address these needs: a complete deployment stack and a comprehensive benchmarking suite.
The Challenge of Local LLM Deployment
While cloud-based LLM services offer convenience, they come with inherent limitations: API costs, data privacy concerns, network dependencies, and usage restrictions. Local deployment solves these issues but introduces new challenges around setup complexity, performance optimization, and system monitoring.
The ideal local LLM environment should be:
- Repeatable: Consistent deployments across different systems
- Performant: Optimized for available hardware, especially Apple Silicon
- Observable: Clear visibility into resource usage and performance metrics
- Maintainable: Easy to update, configure, and troubleshoot
Introducing LLM-Stack: Complete Local Deployment
LLM-Stack provides a turnkey solution for running a complete local LLM environment. The stack combines the power of Ollama’s native Metal acceleration with Docker-based Open WebUI, creating a hybrid approach that maximizes both performance and maintainability.
Architecture Overview
The stack leverages a mixed deployment strategy:
Native Components (Ollama):
- Direct Metal acceleration on Apple Silicon
- Optimal memory utilization through unified memory architecture
- Native macOS integration for maximum performance
Containerized Components (Open WebUI):
- Consistent deployment across environments
- Isolated dependencies and configuration
- Easy updates and rollbacks
- Port-based service discovery
This hybrid approach avoids the performance penalties of containerizing the LLM runtime while maintaining the operational benefits of containerization for the web interface and supporting services.
Key Features
- One-command deployment: Complete stack setup with Docker Compose
- Metal acceleration: Native Apple Silicon optimization through Ollama
- Model management: Integrated tools for downloading and managing models
- Auto-loading tools: Direct support for importing and configuring LLM tools via automated database integration
- System monitoring: Built-in performance and resource tracking
- Configuration management: Environment-based settings for different deployment scenarios
Introducing LLM-Bench: Performance Analysis and Optimization
Understanding how different models perform on your specific hardware is crucial for making informed deployment decisions. LLM-Bench provides comprehensive benchmarking capabilities specifically designed for Apple Silicon systems running Ollama.
Benchmarking Capabilities
The benchmarking suite measures key performance indicators:
Token Generation Speed:
- Tokens per second across different model sizes
- Prompt processing vs generation phase analysis
- Batch size impact on throughput
Memory Utilization:
- RAM usage patterns during inference
- Memory efficiency across model architectures
- Peak memory requirements for capacity planning
CPU and GPU Utilization:
- Metal GPU usage and efficiency
- CPU load distribution
- Thermal and power consumption patterns
Real-World Performance Results
To demonstrate the practical value of systematic benchmarking, here are results from testing on an Apple Studio M2 Ultra with 128GB RAM - a reference platform representing high-end Apple Silicon deployment:
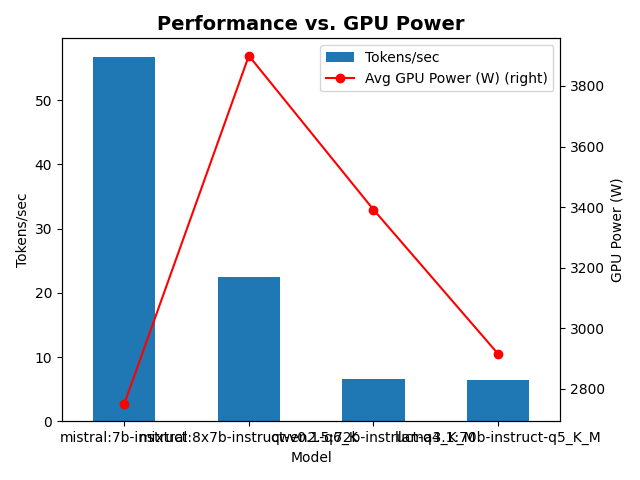
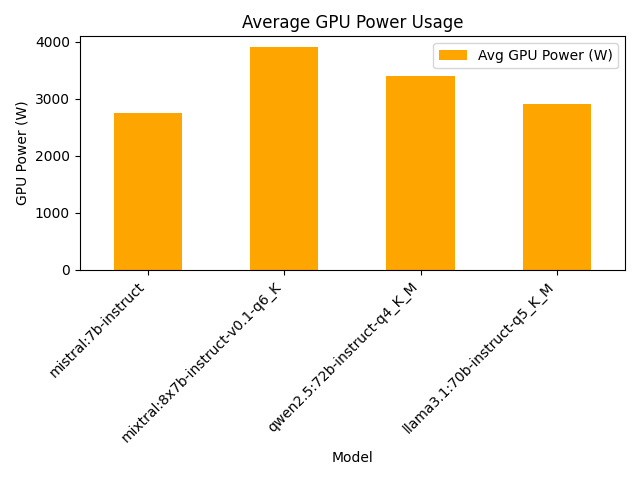
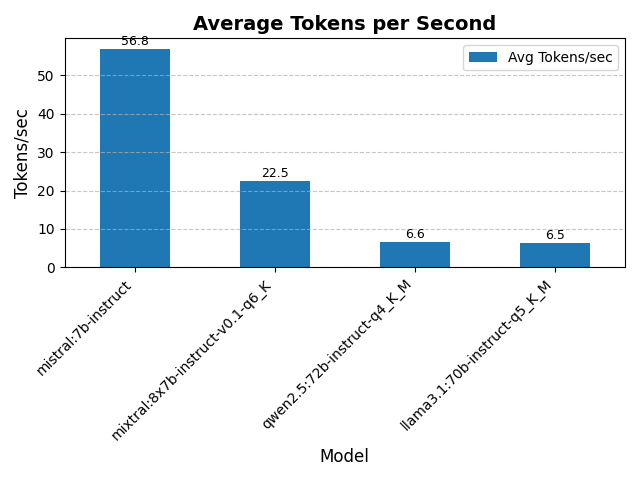
Performance Hierarchy:
- Mistral 7B Instruct: 56.8 tokens/sec at 2,750W GPU power - the clear performance leader
- Mixtral 8x7B Instruct: 22.5 tokens/sec at 3,900W GPU power - balanced performance for larger context
- Qwen2.5 72B Instruct: 6.6 tokens/sec at 3,400W GPU power - high capability, moderate speed
- Llama3.1 70B Instruct: 6.5 tokens/sec at 2,900W GPU power - most power-efficient large model
Key Insights from Benchmarking:
The data reveals important performance characteristics that directly impact deployment decisions. Mistral 7B delivers exceptional speed while maintaining relatively low power consumption, making it ideal for applications requiring rapid response times. The large 70B+ parameter models show interesting power efficiency differences - Llama3.1 70B uses nearly 500W less GPU power than Qwen2.5 72B while delivering comparable token generation speed.
Perhaps most importantly, the performance-vs-power analysis shows that the relationship isn’t linear. Mixtral 8x7B, despite being a mixture-of-experts model with fewer active parameters, consumes the most power while delivering mid-tier performance, suggesting that model architecture significantly impacts hardware utilization on Apple Silicon.
Visualization and Analysis
Performance data is captured and visualized through detailed charts and metrics, enabling:
- Model comparison across multiple dimensions with real performance data
- Hardware optimization identification based on power efficiency curves
- Capacity planning for production deployments using actual resource consumption
- Performance regression detection across updates with historical baselines
The Complementary Ecosystem
These repositories work together to provide a complete local LLM solution:
- Deploy with LLM-Stack: Get a working environment with optimized performance
- Benchmark with LLM-Bench: Understand your system’s capabilities and model performance
- Optimize: Use benchmark data to select the best models for your use case
- Monitor: Leverage built-in monitoring to maintain optimal performance
This approach enables data-driven decisions about model selection, hardware utilization, and system scaling.
Apple Silicon Optimization
Both repositories are specifically optimized for Apple Silicon hardware, taking advantage of:
- Unified Memory Architecture: Efficient memory sharing between CPU and GPU
- Metal Performance Shaders: Native GPU acceleration for inference workloads
- Neural Engine Integration: Hardware-accelerated operations where supported
- Power Efficiency: Optimized for laptop and desktop deployment scenarios
Getting Started
The repositories are designed to work independently or together:
For a complete LLM environment:
git clone https://github.com/rjamestaylor/llm-stack
cd llm-stack
# Follow setup instructions for your environment
For performance benchmarking:
git clone https://github.com/rjamestaylor/llm-bench
cd llm-bench
# Run benchmarks against your Ollama installation
Future Directions
Both repositories are actively developed with planned enhancements including:
- Extended model architecture support
- Additional performance metrics
- Integration with monitoring and alerting systems
- Multi-node deployment capabilities
- Enhanced visualization and reporting features
Conclusion
Local LLM deployment doesn’t have to be complex or poorly understood. By combining a robust deployment stack with comprehensive performance analysis, these tools enable confident local AI deployment with clear visibility into system behavior and capabilities.
Whether you’re running personal AI assistants, developing applications, or conducting research, having both reliable deployment and performance insight is essential for success. These repositories provide that foundation, specifically optimized for the growing ecosystem of Apple Silicon-based development and deployment.
The combination of native performance optimization and containerized operational simplicity represents a pragmatic approach to local AI infrastructure that balances performance, maintainability, and observability.
tags: ollama - metal-acceleration - benchmarking - local-ai - open-webui